
part of the Dictate page series
In order to be able to perform different tasks, there is need to have dictionary in advance, that contains the words, words splitted to sylables and information if sound files are already generated for them.
So the first task is to get the dictionary.
As this project focuses on Bulgarian language dictation, the other languages will be currently ignored.
One possibility is to scrape the required words for example from the Читанка dictionary. It is possible and is not very complicated.
Despite the possibility to download the dictionary DB, first the “brute force” approach will be described- request the word from Читанка and then parse the web page.
Читанка has convenient interface. Adding the word at the end of web request
https://rechnik.chitanka.info/w/[$wordToCheck]
where [$wordToCheck] is actually the cyrilic written word, returns a HTML page. In PS this can be done using
$hDict = @{}
$hDict = $hDict + @{'Accept'='text/html' }
$hDict = $hDict + @{'accept-language'='bg' }
$connuri = "https://rechnik.chitanka.info/w/$wordToCheck"
$response = Invoke-WebRequest -Uri $connuri -Headers $hDict -Method GET
$response.Content | Out-File -FilePath "$saveToRawHTML\$saveToFileFName"The headers are not really required, but this post is also intended for author’s reuse 😉
Читанка responds back with error code when the word is not found, so it is best to use try-catch to be sure that the response is captured.
It is not very difficult to parse teh page, but saving the response to file enables reprocessing, retesting, etc. without requesting the information each time from the web page. Reading the file (if performed from another function/script) can be performed using
$inputContent = Get-Content "$saveToRawHTML\$wordToCheck.html"
$HTML = New-Object -Com "HTMLFile"
[string]$htmlBody = $inputContent
$HTML.write([ref]$htmlBody)
$filter = $HTML.getElementsByClassName('forms-table')
foreach ($tablerEntry in $filter) {
$tableParsed = $tablerEntry.getElementsByTagName('td')
foreach ($singleEntry in $tableParsed) {
$delimitedWord = $singleEntry.innerText |Where-Object {$_ -like "*-*" -and $_ -notlike "* *"}
if ($delimitedWord.Length -gt 0) {
#write to local file ot web dictionary
}
}
}Windows PowerShell HTML parsing is simple. After the delimited words are found, they are added to the dictionary for later reuse. One downloaded web page contains up to 60-70 forms of the word. So all of them are added to the dictionary.
As this approach is suitable for limited words (actually forms of the words) it will not be used.
The second approach is to download the whole DB which Читанка have provided for download under the link . All that is required is to download the MySQL dump files and import them in new database, afterwards extract the splitted words, and move them to new DB, get the sylables
This is done like:
open phpMyAdmin, create new DB, then import the DB
mysql -u tempuser -p 4itanka <db.sqlCreate a query to select the name_broken fromm the derivative_form table and export the results
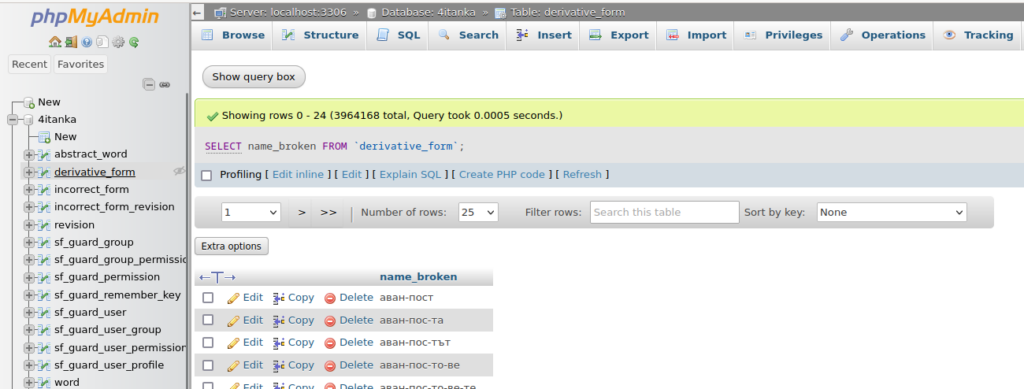
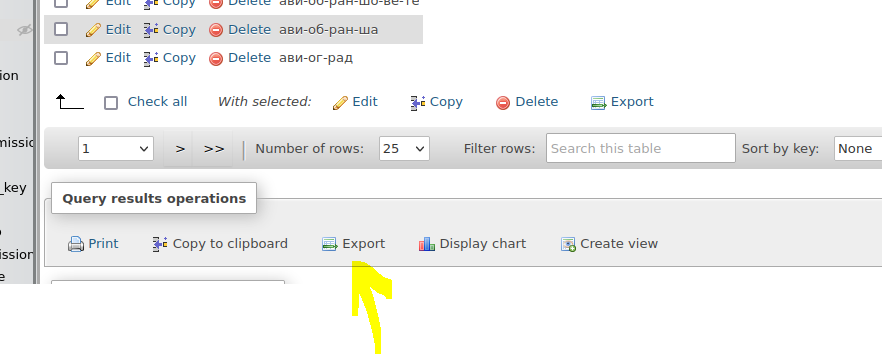
or the splitted words can be saved in new DB like
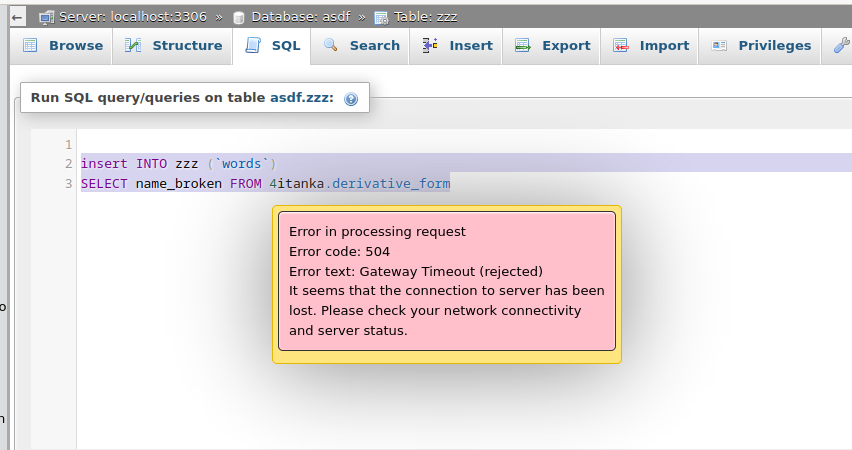
Sometimes phpMyAdmin shows error 504 – Timeout, but usually the action is processed.
The search performance is terrible if the column is not indexed, so it is recommended to add index for example like
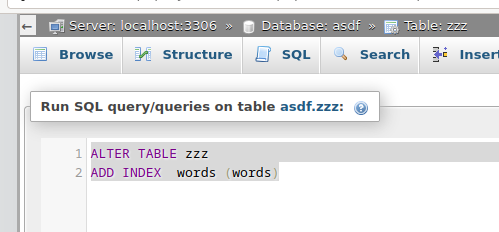
The difference between indexed and non-indexed search is beyond compare (see following screenshots)
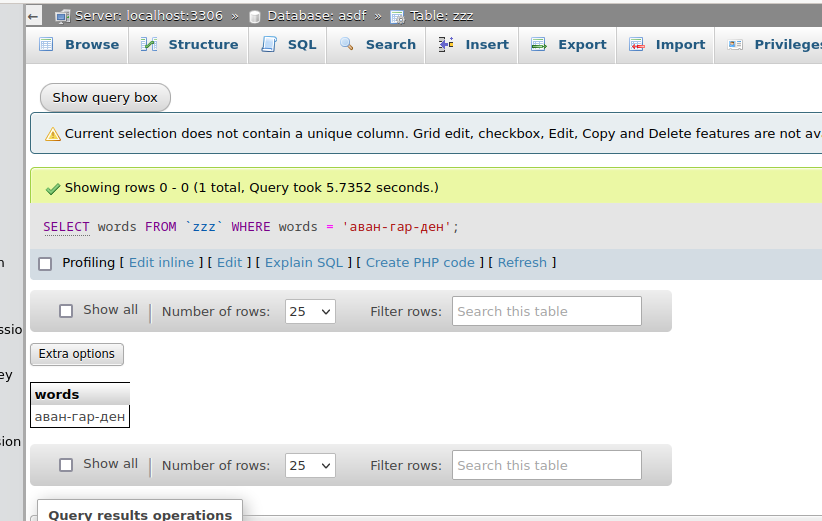
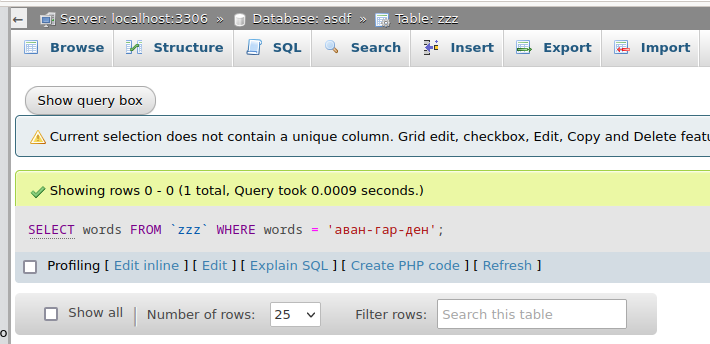
Using new DB is prefered, because of the indexed performance. Despite the nice DB that Chitanka have provided, for this project some customization is required.
The exported words list contains splitted words and also some additional forms, so the records without dashes should be removed. In windows the Notepad can handle the file and in Linux Mouse/Leafpad also.
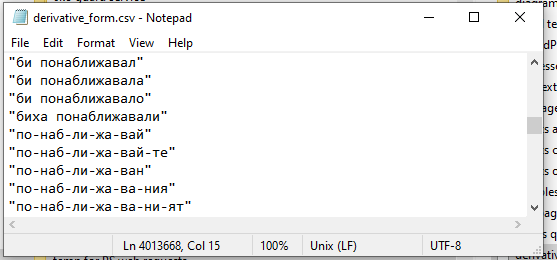
Loading the words in PowerShell takes significant amount of time.
Filtering the words also takes significant amount of time.